5.5 Unüberwachtes Lernen
Auf dieser Seite kann mit wenigen Schritten ein Autoencoder entworfen werden. Ein Autoencoder ist ein speziell aufgebautes neuronales Netz, dessen Schichten symmetrisch aufgebaut sind. Es kann unüberwacht lernen, die Eingabemuster nach Ähnlichkeit zu gruppieren. Dazu wird das symmetrische neuronale Netz mit gleich vielen Eingabe- und Ausgabeneuronen so trainiert, dass es die Eingabe x wieder als Ausgabe ausgibt. Aus diesem Grund werden zum Training auch nur die Eingabedaten x benötigt. Anders formuliert: Es gibt keine Klassen, sondern das neuronale Netz lernt im Laufe des Trainings, seine Eingabedaten wieder als Ausgabedaten auszugeben bzw. so gut wie möglich zu rekonstruieren. Da die Eingabedaten parallel durch das Netz fließen und offensichtlich wenig Information verloren geht, wenn sie am Ende nahezu vollständig rekonstruiert werden können, müssen sie in der Mitte des Netzes automatisch komprimiert worden sein, wenn es dort weniger Neuronen als in der Eingabe- bzw. Ausgabeschicht gibt. Man bezeichnet diese komprimierte Darstellung der Daten in der Mitte des Netzes auch als Latent Space.
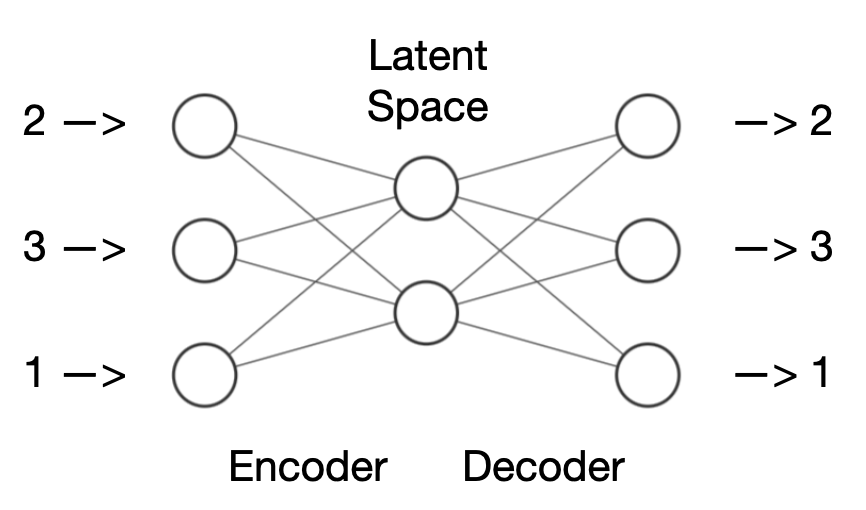
Schematische Darstellung eines Autoencoders
Die Abbildung zeigt beispielhaft ein sehr kleines Autoencoder-Netz: Es gibt drei Eingaben und drei Ausgaben, die den Rahmen bilden. Dazwischen gibt es eine Schicht mit zwei Neuronen. Die beiden Bereiche rechts und links der Mitte werden als Encoder und Decoder bezeichnet. Der Encoder nimmt die Eingabe, in diesem Fall die Zahlen (2,3,1), und komprimiert sie in eine kleinere Darstellung, den Latent Space. Dieser Latent Space enthält eine reduzierte Version der Informationen aus der Eingabe. Anschließend nimmt der Decoder den Latent Space und versucht, die ursprünglichen Zahlen daraus wiederherzustellen. Der Decoder entpackt sozusagen die komprimierten Informationen und generiert eine Rekonstruktion der ursprünglichen Eingabe. Das Interessante daran ist, dass der Autoencoder lernt, wie er die Informationen auf effiziente Weise komprimieren und wiederherstellen kann, ohne dass er spezifisch darauf trainiert wird. Diesen Prozess bezeichnet man als unüberwachtes Lernen.
1. Konstruktion des Autoencoders
Bevor das Netz trainiert werden kann, müssen zuerst die Trainingsdaten in das entsprechende Feld eingegeben werden. Der Autoencoder wird automatisch anhand der erkannten Anzahl der Spalten (maximal 8) konstruiert und die meisten Einstellungen werden auch automatisch getroffen. Um unterschiedliche Arten von Eingabedaten voneinander unterscheiden zu können, kann man diese im Editor zeilenweise markieren und mit einer Farbe versehen (weiter unten gibt es Beispiele, die den Sinn dahinter zum tieferen Verständnis verdeutlichen.) Zu jeder Zeit lassen sich die Werte der Gewichte und Schwellwerte anzeigen, wenn man mit der Maus darüberfährt.
2. Training
Die Trainingsdaten (nur Eingabedaten) müssen durch Leerzeichen bzw. neue Zeilen voneinander getrennt eingegeben werden und aus dem Intervall [0..1] sein. Die Lernrate ist ein Wert, der üblicherweise zwischen 0.01 und 10.0 liegen kann. Je größer der Wert ist, desto schneller, aber auch ungenauer ist das Training und desto größer werden die Gewichts- und Schwellwerte. Die Anzahl an Epochen bestimmt wiederum die Trainingslänge. Eine Epoche ist um, wenn alle Zeilen der Trainingsdaten einmal zum Trainieren benutzt wurden. Das Netz zeigt auf einer Skala von blau (negative Werte) bis rot (positive Werte) an, wie sich die Gewichte und Schwellwerte im Laufe des Trainings verändern.
Die Eingabedaten können entweder auf zwei Werte oder alternativ auf einen Wert komprimiert werden. Im ersten Fall kann die Verteilung der komprimierten Eingabedaten in einem zweidimensionalen Koordinatensystem dargestellt werden und im zweiten Fall auf einer einzigen Linie. Dazu werden die Ausgaben der mittleren Neuron(en) als x- bzw. y-Achsenwerte verwendet. Gleichzeitig werden zu jeder Zeit die Zahlenwerte für die mittlere Schicht und die Ausgabeschicht unterhalb der Grafik angezeigt.
3. Test
Die Verwendung von (neuen) Testdaten ist optional und kann im Anschluss durchgeführt werden. Man ersetzt die Trainingsdaten einfach durch die Testdaten. Zu beachten ist jedoch, dass die Testdaten ebenso durch Leerzeichen bzw. neue Zeilen voneinander getrennt eingegeben werden und aus dem Intervall [0..1] sein müssen. Beim Klick auf Test wird die Repräsentation der Eingabedaten im Latent Space über das Koordinatensystem gelegt und die Ausgabe entsprechend angezeigt.
Beispieldaten
Im Folgenden können Beispieldaten geladen werden, mit denen ein Autoencoder zu Demonstrationszwecken trainiert werden kann. Zum Durchprobieren der Beispiele den jeweiligen Button klicken und danach auf den Button Neu & Train drücken, um zu sehen, wie das Netz trainiert wird und wie es die gelernten Trainingsdaten im Anschluss aus dem komprimierten Latent Space rekonstruieren kann. Die Beispiele sollen verdeutlichen, wie Autoencoder Daten komprimieren können (die sogenannte Dimensionsreduktion) und wie Autoencoder zur Vorhersage von Anomalien sowie zur Rekonstruktion verwendet werden können. Wie bei neuronalen Netzen üblich kann es passieren, dass das Training nicht zum Erfolg führt. Dann kann es helfen, das Netz neu zu laden oder evtl. auch die Werte für die Lernrate oder die Epochen experimentell zu ändern und neu zu trainieren.
(1) Das erste Beispiel ist ein absolutes . Es zeigt sehr schön, wie zwei Eingabewerte auf einen Wert komprimiert werden und später wieder auf zwei Ausgabewerte aufgefaltet werden. Dabei quetscht das neuronale Netz den zweidimensionalen Raum, der durch die beiden Werte x1 und x2 aufgespannt wird zwischendurch auf eine eindimensionale Linie, wie das Minimalbeispiel es ebenso mit Hilfe von Farben zeigt. Dort bleibt die Ordnung zwischen den Farben die ganze Zeit erhalten.
(2) Das nächste Beispiel enthält die Koordinaten eines dreidimensionalen , dessen vordere linke untere Ecke bei (0,0,0) liegt und dessen hintere rechte obere Ecke sich bei (1,1,1) befindet. Während des Trainings kann man gut beobachten, wie die ursprünglich dreidimensionalen Koordinaten auf zwei Dimensionen „gequetscht“ werden und das neuronale Netz dabei versucht, den Abstand zwischen den Punkten möglichst groß zu halten, was daran liegt, dass die acht Punkte keine Ähnlichkeit untereinander haben. Das kleine Netz schafft es übrigens nicht besonders gut, die drei Werte eines jeden Musters komplett richtig wiederherzustellen.
(3) Das folgende verwendet acht Muster mit niedrigen Zahlenkombinationen (schwarz) und acht Muster mit hohen Zahlenkombinationen (grün). Es lohnt sich bei diesem Beispiel, im Anschluss eigene Zahlenkombinationen wie 1.0 1.0 1.0 1.0 einzutippen und auf Test zu klicken. So kann man beobachten, wie ähnliche Zahlenkombinationen (wie übrigens bei allen Beispielen) in ähnliche Regionen des Koordinatensystems projiziert werden.
(4) Der ist weltbekannt. Er besteht aus 150 Eingabemustern (ein Muster pro Zeile). Jedes Eingabemuster hat vier Merkmale. Diese sind die gemessenen Werte in Zentimetern bei 150 unterschiedlichen Schwertlilienarten, und zwar jeweils die Kelchblattlänge, Kelchblattbreite, Kronblattlänge und Kronblattbreite der Blume. Diese vier Werte wurden für 50 Iris setosa (rot), 50 Iris versicolor (grün) und 50 Iris virginica (blau) erhoben und durch 10 dividiert, damit sie in den Wertebereich [0..1] fallen. Die farbliche Markierung der Eingabedaten sorgt dafür, dass man bereits während des Trainings die Lage der drei verschiedenen Blumen-Klassen im Latent Space anhand ihrer Farbe wiederfinden kann. Dabei wird ersichtlich, dass sich die drei Blumenarten am stärksten untereinander ähneln und daher drei nahezu getrennte Gruppen bilden, die man auch als Cluster bezeichnet. Hier zeigt sich auch der Vorteil der Dimensionsreduktion auf zwei Werte: Eine solche Clusterbildung hätte man mit den ursprünglichen vier Werten einer Blume grafisch gar nicht darstellen können.
(5) Autoencoder können neben der Dimensionsreduktion auch zur Rekonstruktion verloren gegangener Daten genutzt werden; z. B. können mit (deutlich größeren und komplexeren) Autoencodern Bilder wiederhergestellt werden, auf denen kleine Teile des Bildes fehlen. Ein Autoencoder, der zuvor mit genug Bildmaterial trainiert wurde, wird diese fehlenden Stellen mit für ihn passenden Inhalten füllen. Dies soll an einem einfachen Beispiel gezeigt werden. Mit einem Klick können hier Daten geladen werden, die pro Zeile jeweils acht Zahlen enthalten, die annähernd einer von 0.2 bis 0.9 entsprechen. Nach dem Training des Autoencoders können geladen werden, in denen der mittlere Wert fehlt bzw. einfach durch 0.0 bzw. 1.0 ersetzt wurde. Mit einem Klick auf Test kann man die beiden Testgeraden mit dem falschen Wert in der Mitte durch das neuronale Netz schicken und beobachten, wie für die Rekonstruktion der Werte im Ausgabefenster o der fehlende Teil durch einen passenden Wert ersetzt wird. Das kann ein Autoencoder, weil er während seines Trainings nur passende Daten kennengelernt hat und nie mit Werten wie 0.0 oder 1.0 an der fehlenden Stelle der Geraden trainiert wurde.
(6) Das vorherige Beispiel lässt sich auch noch weiterdenken, denn Autoencoder können auch dazu verwendet werden, Anomalien in Daten zu entdecken. Angenommen, es gibt vier Sensoren, die bei einem Menschen Temperatur, Puls, Blutzucker und Sauerstoffsättigung messen, und es wurden bereits viele Messungen aufgezeichnet, von denen man weiß, dass sie Normalwerte enthalten. Dann kann man diese Normaldaten in laden (als Minimalbeispiel hier nur vier Zeilen) und damit einen Autoencoder trainieren. (Hinweis: Die Werte wurden durch 100 dividiert, damit sie in das Intervall [0..1] fallen.)
Nach dem Training kann man nun in Testdaten laden und auf Test klicken, um die Daten durch den Autoencoder zu schicken. In den beispielhaften Daten sind zwei Normalmessungen (grün), eine Messung mit zu hoher Temperatur und erhöhtem Puls (rot) und eine Messung mit zu hohem Blutzuckerspiegel (rot) enthalten.
Im Anschluss kann man nun für jede Zeile in oben von Hand oder hier automatisch ausrechnen, wie groß der Unterschied zwischen den Eingabedaten und den rekonstruierten Ausgabedaten ist. Die beiden ersten Messungen sollten zu Werten führen, die nahe an 0 sind, da es sich um Normaldaten handelt. Die beiden letzten Werte sollten jedoch wesentlich höher sein, da sie Abweichungen vom Normalbereich darstellen. Der Autoencoder konnte diese Daten nicht rekonstruieren, weil er nur gelernt hat, Normaldaten zu rekonstruieren. Als letzten Schritt könnte man nun einen Schwellwert einbauen, ab wann der Autoencoder z. B. eine Warnung ausgeben sollte, wenn er Daten erkennt, die außerhalb des Normalbereichs liegen.
Diese Seite teilen

