5.6 Bildgenerierung
Auf der vorhergehenden Seite haben wir den Aufbau eines Autoencoders kennengelernt. Autoencoder kommen in verschiedenen Anwendungen zum Einsatz – u. a. im Bereich der Bildverarbeitung. Zum Beispiel können sie zur Rauschreduzierung in Bildern verwendet werden, indem sie das Bild komprimieren, das Rauschen entfernen und es dann wiederherstellen. Sie können auch (meist in etwas abgewandelter Form) dazu verwendet werden, Bilder zu generieren, was auf dieser Seite in vereinfachter Form gezeigt werden soll.
Im Folgenden wird ein Autoencoder vorgestellt, der mit mehreren hundert Bildern von Äpfeln und Bananen trainiert wurde, die 16x16 Pixel groß waren (mit den Farbkanälen rot, grün, blau). Die Zahlenwerte der Pixel der Bilder wurden dabei ganz einfach und simpel allesamt als Eingabe verwendet, weswegen das Netz auch 768 Eingaben hat (16⋅16 Pixel ⋅ 3 Farben). Wie bei Autoencodern üblich sollte das neuronale Netz lernen, für jede Eingabe genau dasselbe Bild als Ausgabe zu liefern. Zu diesem Zweck bestand die Architektur des Netzes insgesamt aus 768+256+16+4+16+256+768 Neuronen (in der folgenden Abbildung nur schematisch angedeutet).
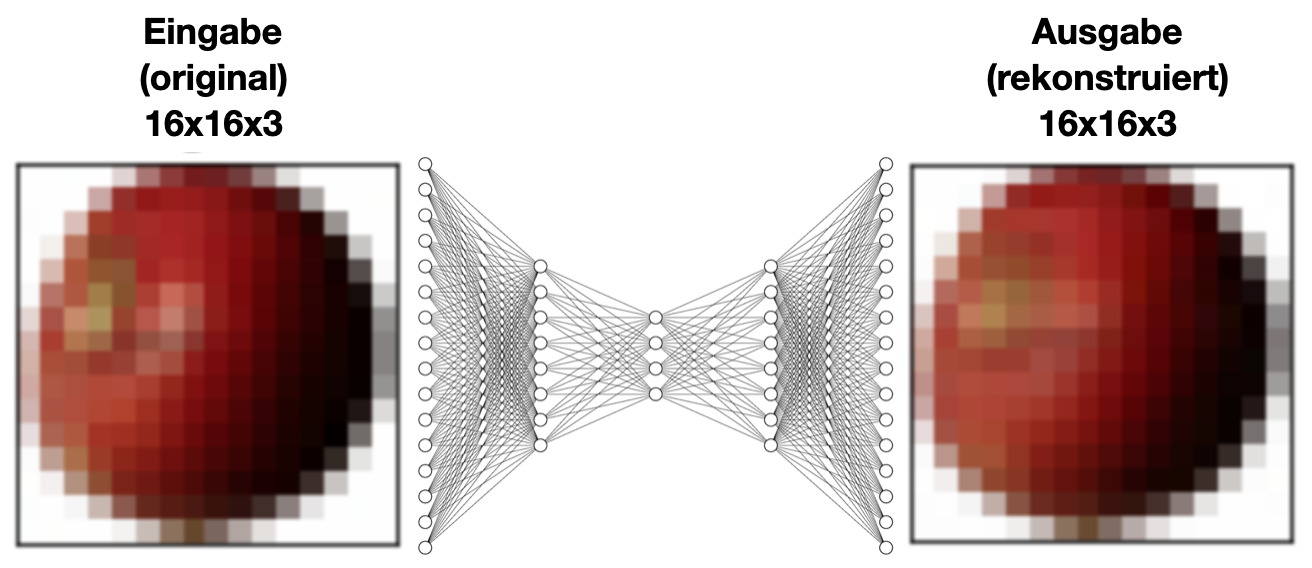
Interessanterweise kann man nach dem Training den Encoder (also den linken Teil) entfernen und nur noch den Decoder verwenden, was im Folgenden auch geschieht. Da jedes Bild auf vier Neuronen und damit auf vier Zahlenwerte reduziert wird (was auch tatsächlich reicht, um das Eingabebild wieder einigermaßen gut rekonstruieren zu können), können mit dem Decoder nun Bilder generiert werden. Dies geschieht, indem die vier Neuronen als Eingaben dienen und man deren Werte verändert. Damit kann man nun sogar Bilder erzeugen, die gar nicht trainiert wurden, z. B. Bilder eines exotischen „Banapfels“.
Anleitung
- Verändere mit Hilfe der vier Schieberegler die Eingabewerte des Decoders auf Werte zwischen 0 und 1. Das aus den vier Werten generierte Bild wird direkt berechnet und angezeigt.
- Hinweis: Der Originaldatensatz zeigte jeweils denselben Apfel bzw. dieselbe Banane aus vielen unterschiedlichen Perspektiven.

Aufgaben
- Probiere, einen Apfel, eine Banane und einen „Banapfel“ zu erzeugen.
- Versuche die Schieberegler so einzustellen, dass seltsame Bilder entstehen, die so sicherlich nicht im Trainingsdatensatz enthalten waren.
Im Folgenden werden einige wenige Auszüge aus den Trainingsdaten des ursprünglichen Autoencoders zusammen mit dem Ergebnis, also der Rekonstruktion der Eingabe, gezeigt. Die Trainingslänge lag bei mehreren hunderttausend Trainingsschritten, bis eine annähernd akzeptable Rekonstruktion erreicht werden konnte. Obwohl jedes Bild auf nur vier Zahlenwerte komprimiert wurde, ist die Rekonstruktion nahezu perfekt. Es muss jedoch gesagt werden, dass das hier gezeigte Vorgehen aus Verständnisgründen recht simpel gehalten wurde. Mit Convolutional Neural Networks ließen sich z.B. gleich viel interessantere Möglichkeiten der Bildgenerierung durchführen, auf die hier jedoch verzichtet wurde.

Trainingsdaten aus Horea Mureşan, Acta Univ. Sapientiae, Informatica Vol. 10, Issue 1, pp. 26-42, 2018.
Datensatz: https://github.com/Horea94/Fruit-Images-Dataset/blob/master/LICENSE
Diese Seite teilen

