5.2 Text
Wie können neuronale Netze Texte verarbeiten oder: Was sind Sprachmodelle?
Neuronale Netze verarbeiten Zahlen und spucken Zahlen aus. Doch wie können sie dann Texte klassifizieren, vergleichen, wiedererkennen, übersetzen und erzeugen? Die Lösung liegt auf der Hand: Dazu müssen auch Texte in Zahlen umgewandelt werden.
Man könnte nun auf die Idee kommen, Buchstaben einfach als Zahlen zu kodieren: A=1, B=2, C=3 usw. Das klappt aber leider nicht. Aus technischer Sicht ginge dies zwar, jedoch käme nichts Vernünftiges dabei heraus, weil das neuronale Netz kein Modell unserer Sprache lernen würde, sondern nur den Zusammenhang, dass A den Wert 1 hat, B den Wert 2 usw. Daher greift man auf einen supereffektiven und erstaunlich einfachen Trick zurück, der im Folgenden erklärt wird: das sogenannte Embedding (wörtlich übersetzt in etwa „Einbetten“ oder auch „Enkodieren“).
Neuronale Netze lernen aus Daten. So ist es auch bei Texten, die sich direkt nutzen lassen, um ein Sprachmodell zu erstellen. Betrachten wir folgende zwölf Sätze, aus denen wir unser Mini-Sprachmodell erstellen wollen. Dabei bestehen alle Sätze aus insgesamt nur 20 Vokabeln:
• Der Junge spielt Fußball auf dem Rasen
• Der grüne Rasen ist schön
• Der Fußball rollt auf dem Rasen
• Auf dem Rasen spielt der Junge
• Der Junge rollt den Fußball
• Auf dem Rasen rollt der Fußball
• Schwarze Raben landen auf dem Rasen
• Raben fliegen über dem Rasen
• Auf dem Fußball landen schwarze Raben
• Der Junge sieht schwarze Raben am Himmel fliegen
• Am Himmel fliegen Raben
• Der Himmel ist schön
Aus den zwölf Sätzen lassen sich unmittelbar 200 Trainingsdaten erstellen, wenn eine Vokabel nun später immer zusammen mit seinen Nachbarn trainiert wird. Dazu werden fortlaufend Paare gebildet: eine Vokabel als Eingabe x und eine benachbarte Vokabel als gewünschte Ausgabe y. Es klingt zunächst wenig plausibel, dass das etwas bringen soll, führt aber dazu, dass Wörter, die oft nebeneinanderstehen, ähnliche Gewichte bekommen, was später noch von Nutzen sein wird. Schauen wir uns einen Beispielsatz an und wie aus den ersten drei Wörtern des Satzes neun Trainingsdaten-Paare erstellt werden. Die Paare werden dabei so gebildet, dass eine Vokabel (gelb markiert) im Idealfall mit allen vier Nachbarwörtern kombiniert wird, von denen sie umgeben ist. Steht die Vokabel selbst z. B. am Anfang eines Satzes, ergeben sich dadurch entsprechend weniger Paare.
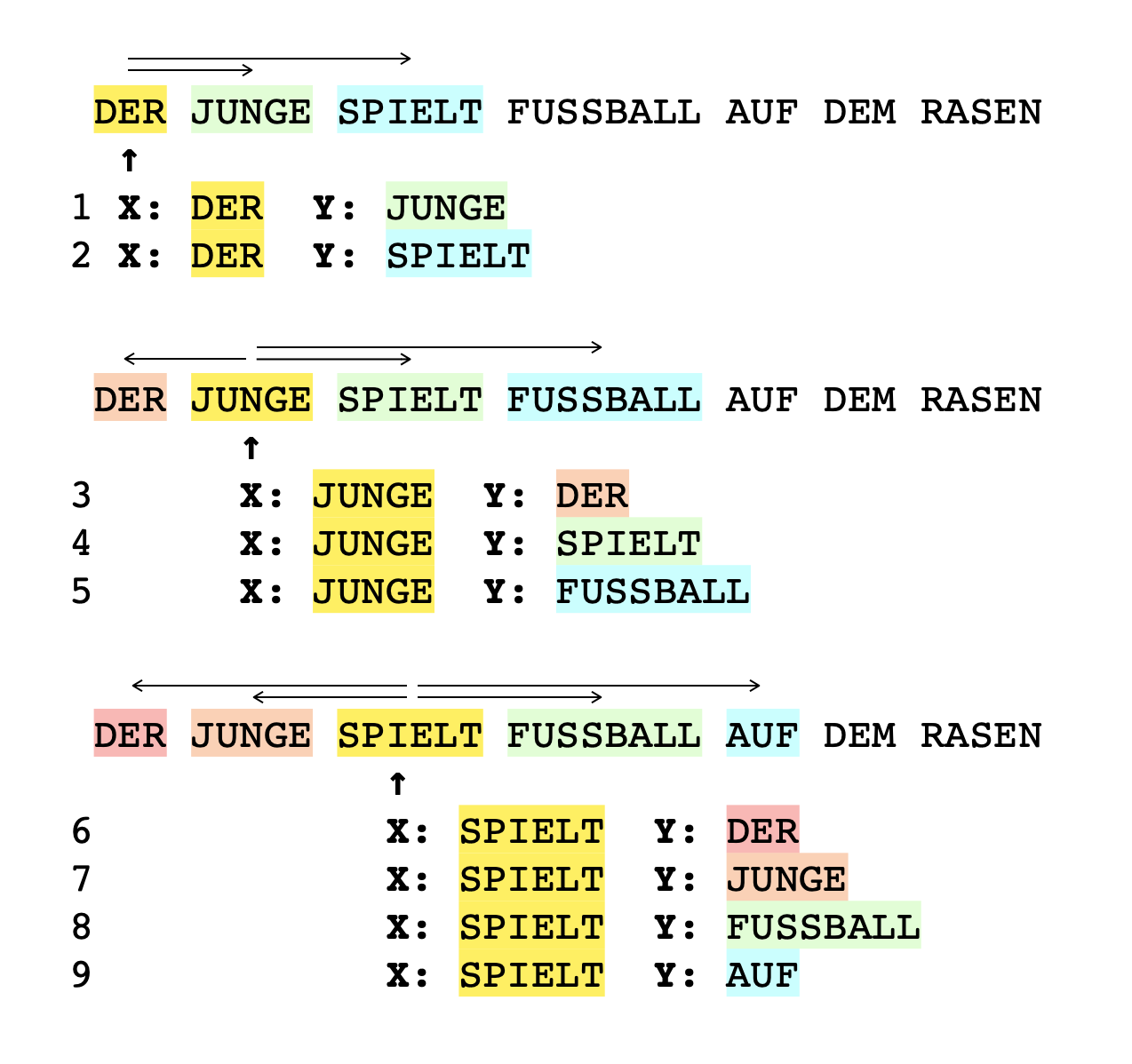
Um die Vokabeln nun für die Weiterverarbeitung mit einem neuronalen Netz aufzubereiten, das für das eigentliche Embedding genutzt wird, wandelt man jede Vokabel in eine Zahl um. Diese Zahl hat die gleiche Anzahl Stellen, wie Vokabeln vorhanden sind. Der Trick hier ist also, jede Vokabel als eine andere Eingabe (und Ausgabe) mit 20 Ziffern darzustellen, bei der alle Ziffern bis auf eine 0 sind (wir haben das bereits als One Hot Encoding kennengelernt):
- "DER" ist das erste Wort, das im Text auftaucht, und wird mit 10000000000000000000 kodiert
- "JUNGE" ist das zweite Wort und wird zu 01000000000000000000
- "SPIELT" bekommt den Wert 00100000000000000000
- ... usw. bis zum letzten Wort "HIMMEL", das zu 00000000000000000001 wird.
Insgesamt ergeben sich aus dem obigen Text mit dieser Vorgehensweise 200 Paare an Trainingsdaten:
Für das eigentliche Embedding nutzt man dann ein neuronales Netz, z. B. wie im Folgenden ein 20-2-20 großes neuronales Netz. Da 20 unterschiedliche Vokabeln vorhanden sind, hat das neuronale Netz 20 Eingaben und 20 Ausgabeneuronen. So kann man jedem Neuron in der Eingabe- und Ausgabeschicht eine Vokabel fest zuordnen (die als 20-stellige Zahl geschrieben an der Position dieses Neurons eine 1 hat). In der mittleren Schicht wählt man als Anzahl der Neuronen die Größe, auf die man eine Vokabel komprimieren möchte. Da die mittlere Schicht in diesem Fall zwei Neuronen enthält, werden pro Vokabel genau zwei Gewichte trainiert, die die Vokabel in Zahlen umgewandelt darstellen. Diese beiden Zahlen sind dann die eingebettete Form.
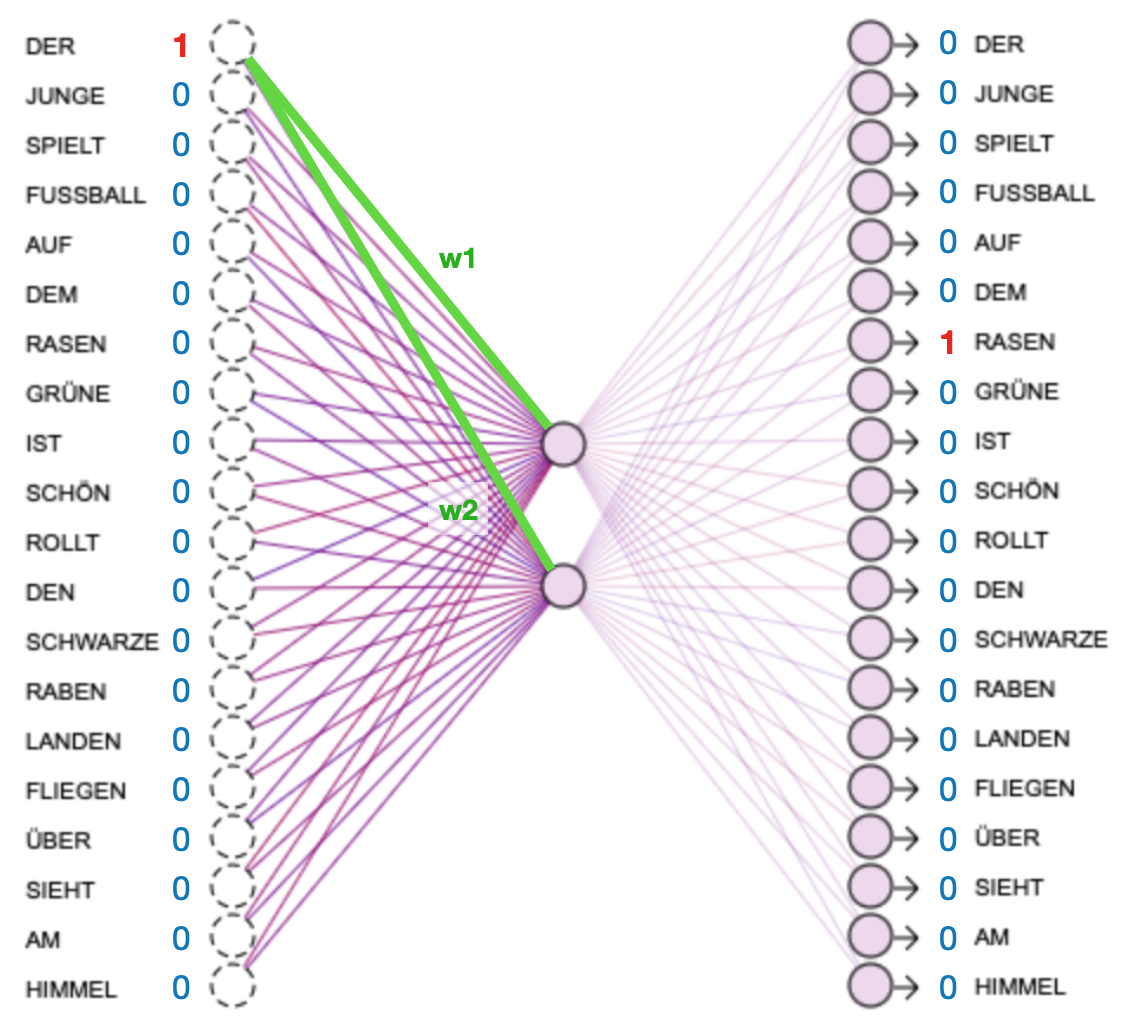
Darstellung des Trainingspaares x:DER / y:RASEN
Da pro Vokabel die beiden Gewichte w1 und w2 trainiert werden, können diese im Anschluss als eingebettete Kodierung der Vokabel und im Folgenden (zur Veranschaulichung) in der interaktiven Abbildung als x- und y-Koordinate dienen. So lässt sich die Ähnlichkeit zwischen den Vokabeln, die das neuronale Netz durch die Trainingsdaten gelernt hat, ganz praktisch und anschaulich darstellen.
Anleitung
- Klicke
Train: Das Netz wird mit den oben abgebildeten Paaren aus Vokabeln trainiert, bis es sie ausreichend gut zuordnen kann. Währenddessen werden die Ähnlichkeiten der Vokabeln zueinander im rechten Teil der Abbildung angezeigt. Jede Vokabel wird ja durch zwei Zahlenwerte (w1 und w2) repräsentiert, die hier als x- und y-Koordinate verwendet werden. Je näher zwei Vokabeln sind, desto ähnlicher sind sie sich inhaltlich. - Klicke
Stop: Der Trainingsprozess wird unterbrochen. Zur Wiederaufnahme des Trainings aufTrainklicken. - Klicke
Reset: Alles, was das Netz gelernt hat, wird zurückgesetzt. Zudem werden neue zufällige Werte für alle Gewichte gewählt. - Klicke auf die Vokabeln im linken Teil der Abbildung. Ihre beiden Werte im eingebetteten Raum sowie ihre Position im rechten Teil der Abbildung werden angezeigt.
Das Modell in der Anwendung
Im Folgenden sollen vier teilweise neue Sätze paarweise verglichen werden. Man könnte vermuten, dass die ersten beiden Sätze die größte Ähnlichkeit zueinander haben, da sie bis auf einen Buchstaben identisch sind. Ist das Netz jedoch trainiert, sieht man deutlich, dass die Sätze nicht nach äußerer Gleichheit, sondern nach innerer Bedeutung gruppiert werden. Vielmehr sollten der erste und der letzte Satz (evtl. auch der zweite und dritte Satz) die größte inhaltliche Ähnlichkeit haben, denn das neuronale Netz kann nun den (sinnvollen) Zusammenhang herstellen, dass Raben im Himmel sind und der Fußball auf dem Rasen.
1. Der Junge sieht Raben
2. Der Junge sieht Rasen
3. Der Junge sieht Fußball
4. Der Himmel ist schön
Dazu werden die x- und y-Koordinaten der enkodierten Wörter aufaddiert und im Anschluss wird die sogenannte Kosinus-Ähnlichkeit der beiden Sätze bestimmt. Dabei handelt es sich um eine sehr simple mathematische Berechnung des Winkels der Zahlen zueinander. Die folgende Tabelle zeigt an, wie ähnlich die Sätze inhaltlich zueinander sind. Dies geschieht auf einer Skala von -1 (gegenteilig) bis 1 (sehr ähnlich).
| Satz 1 | Satz 2 | Ergebnis |
| Der Junge sieht Raben | Der Junge sieht Rasen | |
| Der Junge sieht Raben | Der Junge sieht Fussball | |
| Der Junge sieht Raben | Der Himmel ist schön | |
| Der Junge sieht Rasen | Der Junge sieht Fussball | |
| Der Junge sieht Rasen | Der Himmel ist schön | |
| Der Junge sieht Fussball | Der Himmel ist schön |
Die unten stehenden Formularfelder bieten die Möglichkeit, zwei beliebige Sätze, die auf das Trainingsvokabular zurückgreifen, miteinander auf inhaltliche Ähnlichkeit zu vergleichen. Im Vokabular nicht vorhandene Vokabeln werden dabei ignoriert. Ein Wert nahe 1 deutet auf große inhaltliche Ähnlichkeit hin, während ein Wert nahe -1 nahelegt, dass die Sätze inhaltlich eher entgegengesetzt sind. Dabei wird der Text darunter auch gleichzeitig in seine eingebettete Form übersetzt. Jede Vokabel kann ja nach dem durchgeführten Embedding durch die beiden Zahlen repräsentiert werden, die in der Abbildung noch als x- und y-Koordinaten fungiert haben.
Die eingebettete Form einer Vokabel kann nun für die Weiterverarbeitung mit neuronalen Netzen bestens genutzt werden, da sie nur aus Zahlen besteht und diese Zahlen auch noch die Ähnlichkeit zu denjenigen Vokabeln widerspiegeln, die eine inhaltliche Nähe aufweisen. Ein solches Embedding ist der erste wichtige Schritt für neuronale Netze, die natürliche Sprache verarbeiten. Es ist dabei nicht unüblich, Netze mit über 10.000 Vokabeln (und Eingabe- sowie Ausgabeneuronen) zu verwenden. Statt auf zwei Werte wie im obigen Beispiel bildet man die Vokabeln zur Weiterverarbeitung auf wenige hundert Zahlen ab.
Diese Seite teilen

