5.3 Bilder
Convolutional Neural Networks oder: Wie können neuronale Netze Bilder klassifizieren?
Ein digitales Bild besteht aus sogenannten Pixeln, die für einen Computer nichts anderes als Zahlenwerte sind. Diese lassen sich wiederum als Eingabedaten mit einem neuronalen Netz gut verarbeiten. Der Einfachheit halber werden im Folgenden nur Graustufen-Bilder mit einer Größe von 5x5 Pixeln betrachtet, was bedeutet, dass jedes Bild aus exakt 25 Zahlen besteht, die im Wertebereich zwischen 0 und 1 liegen.
Um ein Gespür dafür zu bekommen, worum es auf dieser Seite geht, kann es durchaus von Vorteil sein, vorab eine richtige Anwendung von Bildverarbeitung mit künstlichen neuronalen Netzen zu benutzen. Dafür eignet sich Google Quickdraw gut. Dort gibt es ein kleines interaktives Programm, das zu erraten versucht, was man am Bildschirm mit der Maus gemalt hat. Dazu bekommt man nacheinander sechs Aufgaben wie z. B.: „Zeichne eine Straßenlaterne in 19 Sekunden.“ In der zur Verfügung stehenden Zeit versucht das Programm, das Gezeichnete so schnell wie möglich richtig zu erkennen. Dabei ist es egal, ob man das Bild links, rechts, oben, unten, groß, klein, nach links oder nach rechts ausgerichtet zeichnet. Meist wird es trotzdem erkannt.
Eine neue Netzarchitektur
Das folgende neuronale Netzwerk in der interaktiven Abbildung funktioniert prinzipiell ähnlich wie das neuronale Netz von Quickdraw – nur sehr stark vereinfacht. Es ist ein sogenanntes Convolutional Neural Network. Neben den bekannten Komponenten bringt es drei neue Konzepte mit: einen Filter, eine spezielle Schicht, die sich Convolution nennt, und eine spezielle Schicht, die man Max Pooling nennt. Um es gleich vorwegzunehmen: Bei neuronalen Netzen in der Größenordnung von Googles Quickdraw sind diese drei neuen Konzepte nicht jeweils einmal, sondern zigmal im Netz vorhanden. Ein typisches Convolutional Neural Network besteht dabei aus mehreren bis vielen Schichten Convolution und Max Pooling, bevor sich am Ende ein „normales“ neuronales Netz anschließt, wie wir es bisher kennengelernt haben. Auch wenn dies zunächst kompliziert klingt, in den neuen Schichten finden lediglich simple mathematische Berechnungen statt, die in der interaktiven Grafik gut nachvollzogen werden können.
Diese Seite verwendet das einfachst mögliche Convolutional Neural Network, damit es Schritt für Schritt nachvollzogen werden kann. Es besteht aus einer einzigen Kombination von Convolution und Max Pooling und hat nur einen einzigen Filter. Zudem kann es lediglich Bilder aus zwei Klassen (im Beispiel unten: schwarz – weiß) klassifizieren, die maximal 5x5 Pixel groß sind – also ein echtes Minimalbeispiel.
Funktionsweise
Der Filter besteht aus 3x3 Zahlen, die zusätzlich zu den acht normalen Gewichten und zwei Schwellwerten trainiert und damit verändert werden. Der Filter wird von links oben nach rechts unten über das Eingabebild geschoben, und in jedem Schritt werden alle Werte mit den Zahlenwerten des Bildes multipliziert und aufaddiert. So entsteht eine kleinere Abbildung des ursprünglichen Bildes. Über dieses neue Bild wird wiederum ein 2x2-Fenster geschoben und der jeweils maximale Wert herauskopiert. Schlussendlich wird so aus dem 5x5-Raster ein 2x2-Raster, das vier Werte enthält, die nun als Eingabe in das „normale“ neuronale Netz dienen.
In der interaktiven Abbildung lassen sich drei unterschiedliche Beispieldatensätze laden. Das Netz kann mit den angezeigten Trainingsdaten trainiert und mit den Testdaten am unteren Rand der Abbildung getestet werden. Dabei wird auch die Vorhersage angezeigt, wofür das Netz das Eingabebild hält. Zusätzlich kann die Berechnung des Netzes Schritt für Schritt animiert werden.
Anleitung
- Klicke auf die Auswahl, um die Beispiele 1 bis 3 zu laden (vertikale vs. horizontale Linien, Quadrate vs. Kreuze oder Äpfel vs. Bananen). Ein erneuter Klick mischt die Verteilung der Trainings- und Testdaten neu.
- Klicke auf
Train, um das Netz mit den ausgewählten Daten zu trainieren. Ist der Fehler am Ende des Trainings noch zu hoch, hilft ein erneuter Klick aufTrainoder das Neuladen des Datensatzes mit anschließendem Klick aufTrain. - Klicke auf ein Vorschaubild aus den Testdaten am unteren Rand. Für das ausgewählte Bild werden die Berechnung und die Vorhersage des Netzes angezeigt.
- Klicke auf
Animation. Die Berechnung des Netzes für das aktuell aus den Testdaten ausgewählte Bild wird Schritt für Schritt animiert. Die Abspielgeschwindigkeit der Animation kann mit dem Schieberegler (schnell bis langsam) eingestellt werden. - Klicke in den freien Raum der Abbildung, um die Berechnungen und Vorhersagen wieder auszublenden.
- Blau steht in der Abbildung für negative Werte und rot für positive Werte.
Mehr Filter und größere Netze
Vielleicht ist es bei den ersten beiden Beispielen aufgefallen: Da der Filter während des Trainings mittrainiert wird, entwickelt er im Lauf der Zeit ein Muster, das besonders gut geeignet ist, Merkmale der beiden Klassen zu unterscheiden. Oftmals findet sich im Filter eine grafisch sichtbare Struktur wie eine horizontale, vertikale oder diagonale Linie wieder – je nach vorhandenen Trainingsdaten.
Je mehr Filter dementsprechend in einem neuronalen Netz vorhanden sind, desto mehr Merkmale und Strukturen lassen sich identifizieren. Im Prinzip reicht ein Filter das Vorhandensein eines Merkmals in Form von Zahlen nach rechts zur eigentlichen Klassifikation durch. Daher ist es höchst sinnvoll, möglichst viele Filter zu haben, um verschiedene Klassen anhand verschiedener Merkmale und Strukturen voneinander unterscheiden zu können. Während es im obigen Minimalbeispiel exakt 19 Parameter gibt (9 Filterwerte, 8 Gewichte, 2 Schwellwerte), benutzen moderne High-Performance-Netze zur Bildklassifikation mehr als 2 Milliarden Parameter, da in diesen Netzen nicht selten Datensätze mit 1000 Klassen oder mehr verwendet werden.
Prinzipiell kann man das obige Beispiel schrittweise erweitern, indem mehr Filter hintereinandergeschaltet werden (seriell) und gleichzeitig mehr Filter parallel nebeneinandergeschaltet werden. Da alle Filter mit zufälligen Startwerten erstellt werden, erkennen sie mit hoher Wahrscheinlichkeit auch unterschiedliche Merkmale in den Bildern – vor allen Dingen, wenn der Datensatz groß genug ist, was ohnehin das A und O beim Training von neuronalen Netzen ist.
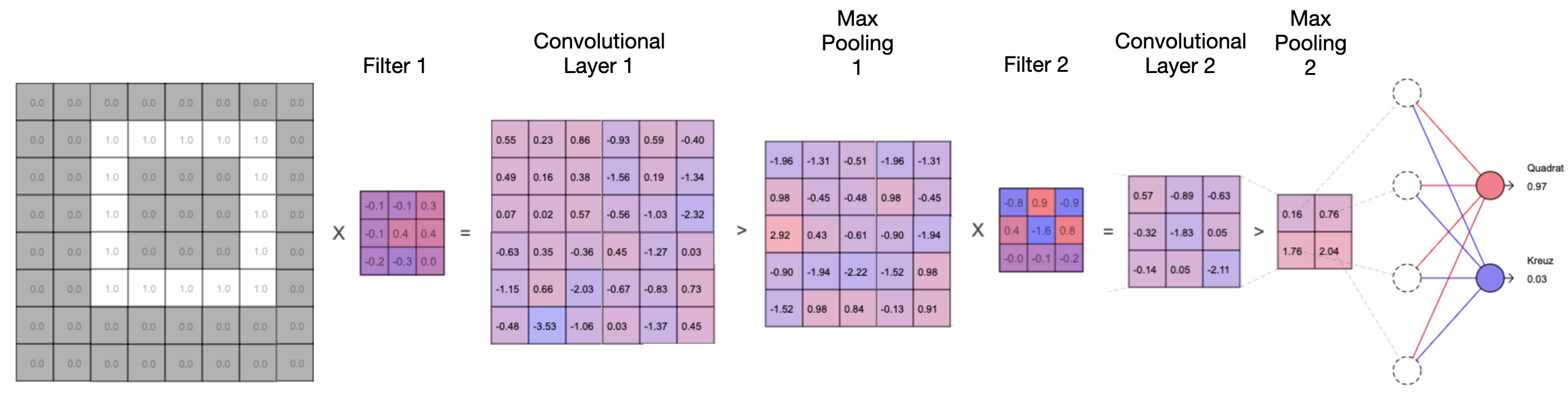
Vereinfachte Serienschaltung von Filtern am Beispiel von zwei Filtern
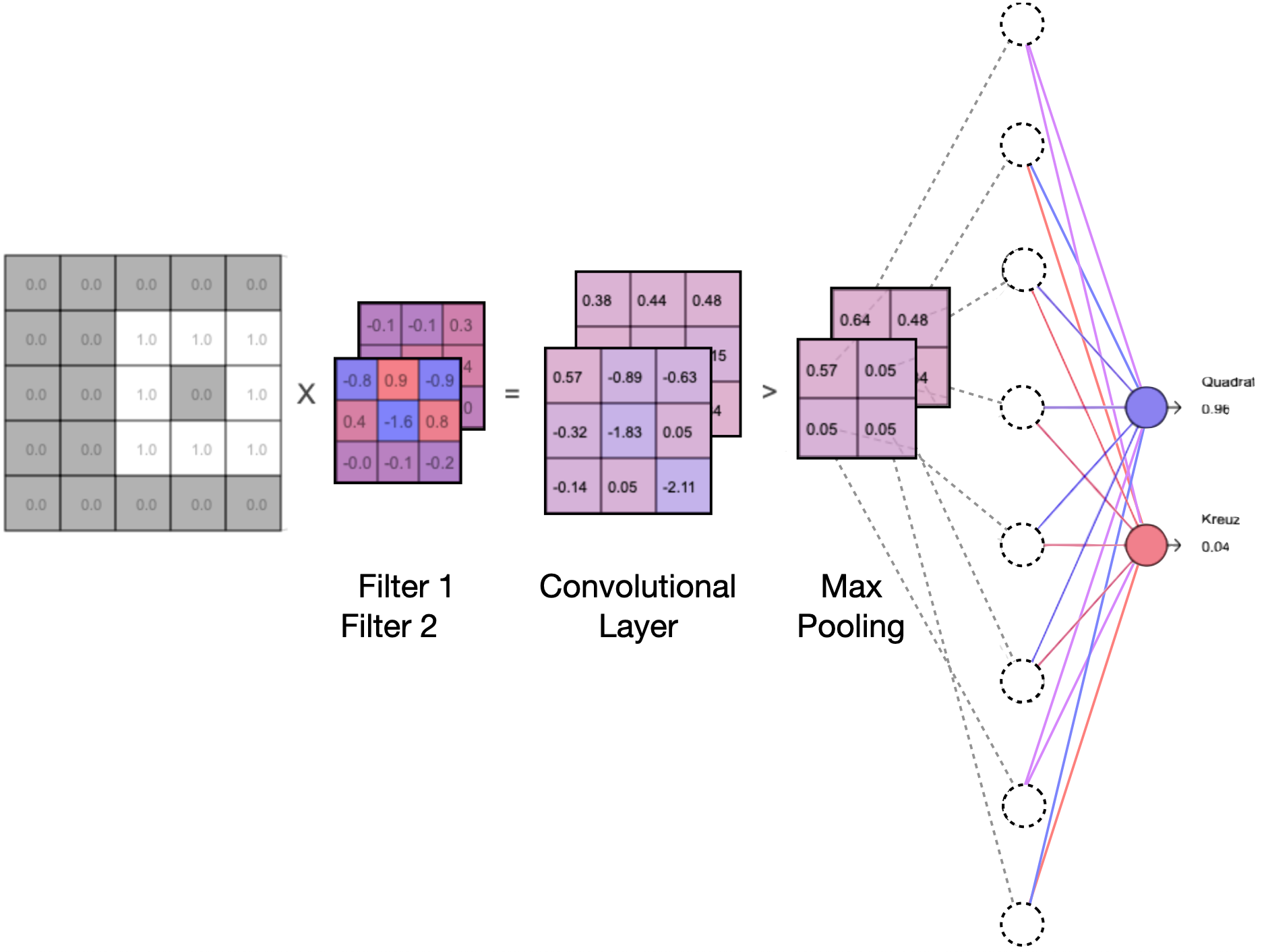
Parallelschaltung von Filtern am Beispiel von zwei Filtern
Umlernen
Ein gut funktionierendes Convolutional Neural Network besitzt viele Filter, die die Merkmale von Bildern geschickt nach rechts durchreichen. Bei erfolgreichem Training funktionieren die Filter dann sogar so gut, dass es egal ist, ob eine vertikale Linie rechts oder links, mittig, oben oder unten, groß oder klein gezeichnet wird. Die Information der vertikalen Linie wird trotzdem nach rechts durch das Netz gereicht.
Daher ist es nun möglich, den vorderen Teil (bestehend aus Filtern, Convolution- und Max-Pooling-Schichten) einzufrieren (wenn er hervorragend funktioniert) und nur den hinteren Teil (normales neuronales Netz) umlernen zu lassen. Mit anderen Worten: Hat man ein Netz, das Äpfel und Birnen gut erkennt, so wird der vordere Teil des Netzes gute Filter entwickelt haben, die dies möglich gemacht haben. Diese Filter kann man nun unverändert lassen und den hinteren Teil darauf trainieren, dass er z. B. 1 0 für Birnen und 0 1 für Pflaumen ausgibt oder 1 0 für Bilder von Marienkäfern und 0 1 für Bilder von Raupen. Exakt diese Vorgehensweise (ein bestehendes gut funktionierendes Netz umzutrainieren) wird z. B. bei Bildprojekten von Googles Teachable Machine verwendet.
Kreatives zum Abschluss
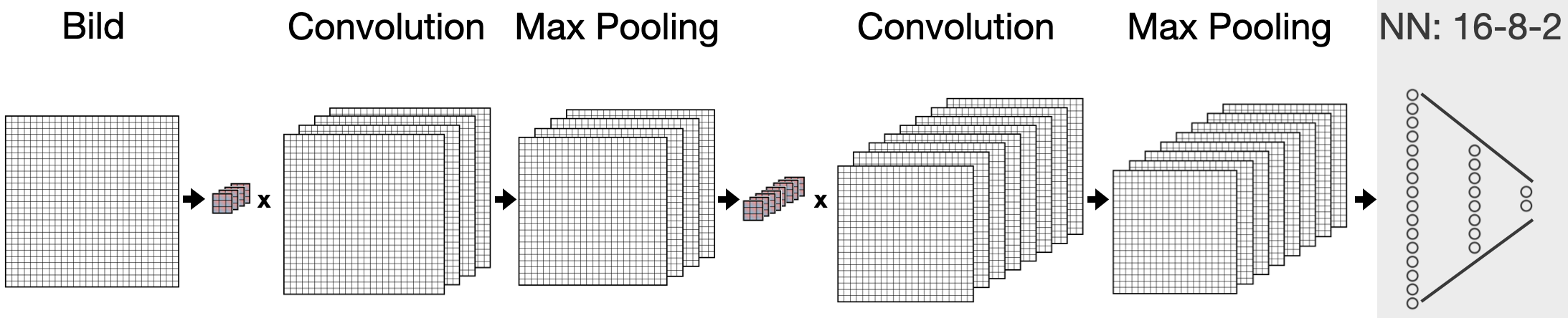
Ein geringfügig größeres Convolutional Neural Network als im obigen Beispiel wird im Folgenden verwendet, um Zeichnungen, die man selbst anfertigen kann, in die Klassen Apfel und Banane einzuordnen. Das bereits trainierte neuronale Netz wurde mit Bildern trainiert, die 28x28 Pixel groß sind. Die Bilder stammen aus den Trainingsdaten von Google Quick, Draw! und enthalten handgezeichnete Skizzen von Äpfeln und Bananen.

Das verwendete neuronale Netz hat 4 parallele Filter in der ersten Convolution-Schicht, danach eine Max-Pooling-Schicht mit 2x2-Fenster, dann folgen 8 parallele Filter in der zweiten Convolution-Schicht, wiederum gefolgt von einer Max-Pooling-Schicht, bevor das eigentliche neuronale Netz folgt, mit 16 Neuronen in der ersten Schicht, 8 Neuronen in der zweiten Schicht und 2 Ausgabeneuronen.
Anleitung
- Zeichne mit der linken Maustaste einen (am besten großen) Apfel oder eine Banane und klicke auf Test. Das Netz berechnet die Vorhersage, ob es deine Zeichnung eher für einen Apfel oder für eine Banane hält.
- Klicke
Reset, um deine Zeichnung rückgängig zu machen.
Diese Seite teilen

